Spheron and Heurist Take on AI Innovation

In this exciting crossover episode of Tech Fusion, we dive deep into the world of AI, GPU, and decentralized computing. This discussion brings together minds from Spheron and Heurist to explore cutting-edge innovations, challenges, and the future of technology in this space. Let’s jump straight into the conversation where our host Prashant (Spheron’s CEO) and JW and Manish from Heurist take center stage.
If you want to watch this episode, click below or head over to our YouTube channel.
Introduction to the Tech Fusion Episode
Host: “Welcome, everyone! This is Episode 9 of Tech Fusion, and we’re in for a treat today. This is our first-ever episode featuring four guests, so it’s a big one! I’m Prashant, and Prakarsh from Spheron is with me today. We have special guests from Heurist Manish and JW. It’s going to be a deep dive into the world of AI, GPUs, decentralized computing, and everything in between. So let’s get started!”
The Evolution of AI Models and Decentralized Computing
Prashant: “JW and Manish, let’s start by talking about AI models. We’ve recently seen advancements in AI reasoning capabilities, and it’s clear that decentralized computing is catching up. How long do you think it will take for end-users to fully harness the power of decentralized AI models?”
JW (Heurist): “Great question. First off, thank you for having us here! It’s always exciting to share thoughts with other innovative teams like Spheron. Now, on AI reasoning—yes, OpenAI has been making waves with its models, and we’ve seen open-source communities attempt to catch up. Generally, I’d say the gap between open-source and closed-source AI models is about six to twelve months. The big companies move faster because they have more resources, but the open-source community has consistently managed to close the gap, especially with models like LLaMA catching up to GPT-4.”
Challenges in Training and Inference with Decentralized GPUs
Prashant: “Decentralized computing is a hot topic, especially in how it relates to the scalability of training and inference models. JW, you mentioned some experiments in this space. Could you elaborate?”
JW: “Absolutely! One exciting development comes from Google’s research into decentralized training. For the first time, we’ve seen large language models (LLMs) trained across distributed GPUs with minimal network bandwidth between nodes. What’s groundbreaking is that they’ve reduced network transmission by over a thousand times. It’s a big leap in showing that decentralized compute isn’t just theoretical—it’s real and can have practical applications.”
The Role of VRAM and GPU Pricing in AI Models
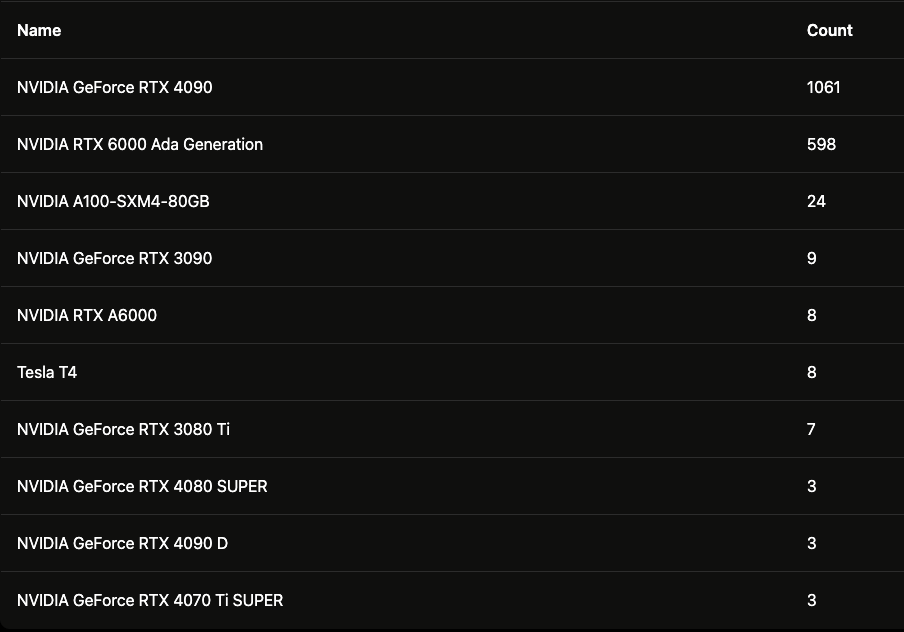
Prakarsh (Spheron): “That’s fascinating. Something that I find equally intriguing is the premium we’re paying for VRAM. For instance, an H100 GPU has 80 GB of VRAM, while a A6000 has 48 GB. We’re essentially paying a high premium for that extra VRAM. Do you think we’ll see optimizations that reduce VRAM usage in AI training and inference?”
Manish (Heurist): “You’re absolutely right about the VRAM costs. Reducing those costs is a huge challenge, and while decentralized computing might help alleviate it in some ways, there’s still a long road ahead. We’re optimistic, though. With technologies evolving, particularly in how models are optimized for different hardware, we may soon see more cost-efficient solutions.”
Decentralized Compute’s Impact on AI Training and Inference
Prashant: “So, let’s dig deeper into the training versus inference debate. What’s the biggest difference you’ve seen between these two in terms of cost and resources?”
JW: “Great question. Based on our data, about 80-90% of compute resources are spent on inference, while only 10% goes to training. That’s why we focus heavily on inference at Heurist. Inference, although less resource-intensive than training, still requires a robust infrastructure. What’s exciting is how decentralized compute could make it more affordable, especially for end-users. A cluster of 8 GPUs, for instance, can handle most open-source models. That’s where we believe the future lies.”
The Vision for Fizz Node: Decentralized Inferencing
Prashant: “At Spheron, we’re working on something called Fizz Node, which allows regular computers to participate in decentralized inferencing. Imagine users being able to contribute their GPUs at home to this decentralized network. What do you think of this approach?”
JW: “Fizz Node sounds incredible! It’s exciting to think of regular users contributing their GPU power to a decentralized network, especially for inference. The idea of offloading lower-compute tasks to smaller machines is particularly interesting. At Heurist, we’ve been considering similar ideas for some time.”
Technological Challenges of Distributed Compute
Prakarsh: “One challenge we’ve seen is the efficiency of decentralized nodes. Bandwidth is one thing, but VRAM usage is a critical bottleneck. Do you think models can be trained and deployed on smaller devices effectively?”
Manish: “It’s possible, but it comes with its own set of complexities. For smaller models or highly optimized tasks, yes, smaller devices can handle them. But for larger models, like 7B or 45B models, it’s tough without at least 24 GB of VRAM. However, we’re optimistic that with the right frameworks, it can become feasible.”
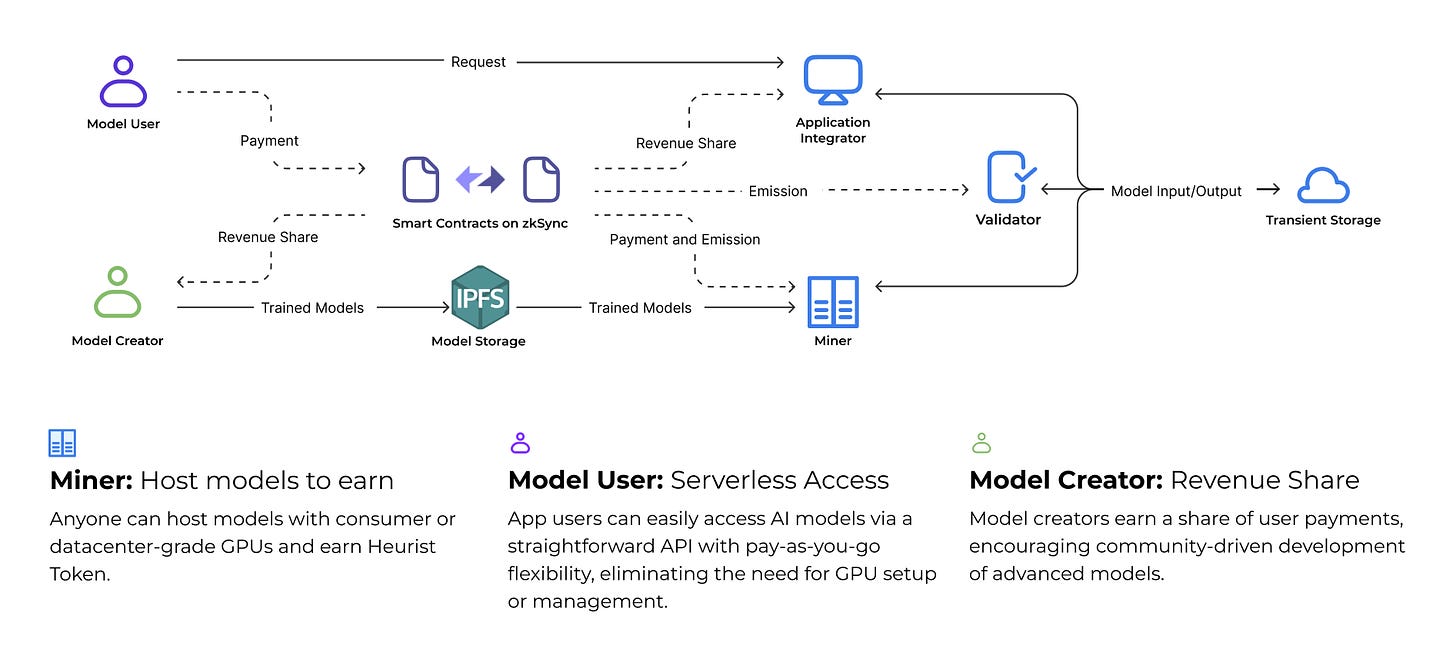
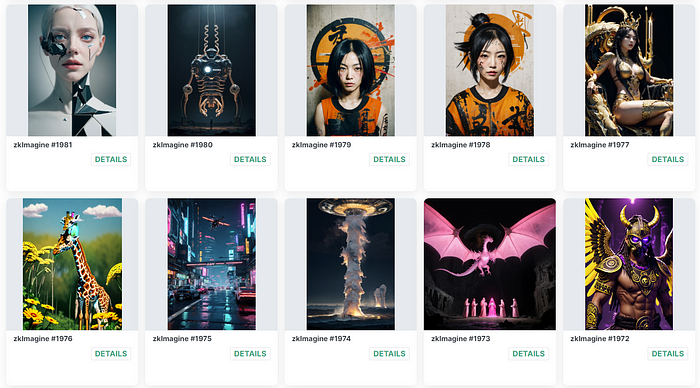
Prashant: “I noticed Heurist has built several interesting tools like Imagine, Search, and Babel. How did those come about, and what’s the community response been like?”
JW: “The main goal of our tools is to make AI accessible and easy to use. When we launched Imagine, an AI image generator, the response was overwhelmingly positive. It stood out because we fine-tuned models specifically for our community—things like anime style or 2D art. It really showcased how diverse open-source AI could be. We’ve seen huge adoption in the Web3 space because users don’t need a wallet or even an account to try them. It’s all about creating a seamless user experience.”
AI-Driven Translation: Bringing Global Communities Together
Prashant: “Speaking of seamless experiences, I’m intrigued by your Discord translation bot. It sounds like a game-changer for communities with users from all over the world.”
JW: “It really is! The bot helps our community communicate across languages with ease. We wanted to make sure that AI could bridge language barriers, so now, anyone can send messages in their native language, and they’ll automatically be translated for the rest of the group. It’s been a huge hit, especially with our international users.”
Exploring Cursor: A Developer’s Dream Tool
Prakarsh: “Recently, I’ve heard developers rave about Cursor as a coding assistant. Have you integrated Cursor with Heurist?”
Manish: “Yes, we’ve tested Cursor with our LLM API, and the results have been fantastic. It feels like having multiple interns working for you. With AI-driven development tools like Cursor, it’s becoming much easier to code, even for those who’ve been out of the loop for years.”
The Future of AI: What’s Next for Spheron and Heurist?
Prashant: “Looking ahead, what are Heurist’s plans for the next couple of months?”
JW: “We’re working on some exciting things! First, we’ll be sponsoring DEFCON, and we’re collaborating with an AI partner to promote our Heurist API services. We’re also finalizing our tokenomics for the Heurist network, which we’re really excited about. We’ve been putting a lot of effort into designing a sustainable economic model, one that avoids the pitfalls we’ve seen in other projects.”
Final Thoughts: AI, GPUs, and Beyond
Prashant: “Before we wrap up, let’s talk about the episode’s title, AI, GPUs, and Beyond. What do you think the ‘beyond’ part will look like in the next few years?”
JW: “I believe AI will become so integrated into our daily lives that we won’t even notice it. From how we browse the web to how we work, AI will power much of it without us even being aware of it.”
Manish: “I agree. AI will blend seamlessly into the background, making everything more efficient. The future is in making these technologies invisible but essential.”
Conclusion
This episode of Tech Fusion was a fascinating exploration of how AI, GPUs, and decentralized compute will shape our future. From the challenges of VRAM usage to the exciting potential of Fizz Node and Heurist’s ecosystem, it’s clear that the landscape of technology is rapidly evolving. If you haven’t already, now is the time to dive into the world of decentralized AI and GPU computing!
FAQs
1. What is Fizz Node, and how does it work?
Fizz Node allows regular users to contribute their GPU power to a decentralized network, particularly for AI inferencing tasks. It optimizes small-scale devices to handle lower-compute tasks efficiently.
2. What is the difference between AI training and inference?
Training involves teaching the AI model by feeding it data, whereas inference is the process of applying the trained model to new inputs. Inference typically requires fewer resources than training.
3. How does Heurist’s Imagine tool work?
Imagine is an AI-driven image generation tool that allows users to create art in different styles, from anime to 3D realistic models, using fine-tuned models developed by the Heurist team.
4. What makes Heurist’s translation bot unique?
Heurist’s translation bot enables seamless communication across languages in Discord communities, automatically translating messages into the preferred language of the group.
5. What’s the future of decentralized GPU computing?
The future lies in making decentralized computing more accessible, cost-effective, and scalable, potentially competing with centralized giants like AWS. The goal is to decentralize much of the current AI compute load.