TakeMe2Space, a pioneering SpaceTech startup, has successfully raised ₹5.5 crore in a pre-seed funding round led by Seafund, with participation from Blume Ventures, Artha Venture Fund, AC Ventures, and other prominent angel investors. This funding will fuel the development and launch of MOI-1, India’s first AI-powered space laboratory, aimed at revolutionizing satellite research and data processing in space.
Founded in 2024 by Ronak Kumar Samantray, TakeMe2Space has already made remarkable progress, completing two successful missions in collaboration with ISRO’s POEM (Payloads and Orbital Experiments Module) platform. During these missions, the company demonstrated an innovative radiation shielding coat, a key technology that will play a crucial role in future space applications.
Pioneering Space Research and AI Integration:
TakeMe2Space is committed to enhancing India’s capabilities in radiation shielding, propulsion systems, and inter-satellite communication. With MOI-1, the company will offer over 15 early customers the ability to run orbital applications on an AI-driven platform, accelerating space-based research and development.
In the past year, the company has rapidly expanded its team to over 17 engineers, who have contributed to the development of more than 15 satellite sensors and subsystems. Its MOI-TD mission has already achieved a significant breakthrough, proving the feasibility of uplinking large AI models, executing external code on satellites, and securely downlinking encrypted results. The mission also successfully validated critical components, including:
Advanced sensors (Sun Sensor, Horizon Sensor, Solar Cell, IMUs)
Computing infrastructure (Zero Cube AI Accelerator, POEM Adapter Board)
Global Expansion and Future Plans:
With its go-to-market strategy focused on India, Australia, and Europe, TakeMe2Space aims to deploy its satellite subsystems internationally, making AI-powered space research more accessible. Over the next 12 months, the startup is set to double its revenue, expand its product portfolio, and strengthen its R&D efforts.
Industry Leaders Endorse TakeMe2Space’s Vision:
Manoj Kumar Agarwal, Managing Partner at Seafund, emphasized the potential of SpaceTech, stating:
“Emerging technologies like space tech have the potential to unlock impactful solutions at scale. The Indian space industry has made remarkable progress, and government initiatives will further accelerate growth. TakeMe2Space’s MOI-1 launch will be a key milestone in the development of space-based data centers, and this funding will help the company expand its satellite subsystems globally.”
Ronak Kumar Samantray, Founder and CEO of TakeMe2Space, highlighted the significance of this investment, saying:
“This funding reflects our team’s dedication and the impact we are making in the SpaceTech industry. With this support, we look forward to accelerating our growth and bringing our first AI lab to more customers worldwide.”
TakeMe2Space’s ambitious roadmap positions it as a trailblazer in India’s SpaceTech ecosystem, set to redefine AI-driven satellite research and innovation on a global scale.
For more insights and updates on Metaverse, DeFi, Blockchain, NFT & Web3, be sure to subscribe to our newsletter. Stay informed on the latest trends and developments in the decentralized world!
Flowdesk, a French crypto trading firm with expertise in market making and liquidity provision, has raised $52 million in an extension funding round, taking its overall funding to $102 million. The new capital, raised through a combination of equity and debt, will fuel the company’s expansion into new geographies and the opening of a dedicated crypto-credit desk.
Strategic Funding Breakdown:
The round was led by HV Capital in the equity component, with Eurazeo, Cathay Innovation, and ISAI VC also chipping in. BlackRock-managed funds contributed the debt capital. Interestingly, HV Capital has gained a seat on the board of Flowdesk in return for its investment.
Guilhem Chaumont, Flowdesk’s co-founder and global CEO, emphasized that the firm’s decision to take on debt was a strategic move to scale sustainably without significant equity dilution.
“We will do so not only with equity or our own profits. That’s why we chose the path of debt, which is a non-dilutive option for us,” Chaumont explained, highlighting the company’s strong financial position and ability to repay debt easily.
Even with the funding, Flowdesk was not actively looking for new investments but was shown high interest from several investors, leading to the capital raise. The firm’s earlier $50 million Series B round in January 2024 valued it at $250 million. With this latest funding, the aggregate Series B funding is now $102 million.
Expansion Plans and the Crypto-Credit Desk:
Flowdesk is gearing up to take advantage of the increasing demand for the tokenization of real-world assets and it’s over the counter (OTC) derivatives operations. One key focus will be opening up a specific crypto-credit desk to bridge the gap in the market for lending services.
Beyond the crypto-credit initiative, Flowdesk is investing in proprietary trading infrastructure and enhancing compliance frameworks. Chaumont noted,
“We’re building solutions that are transparent, scalable, fast, and competitive, spanning the full spectrum of assets—from majors to meme coins, and eventually tokenized securities.”
In order to help its expansion, Flowdesk aims to double the size of its staff in a year. It will also have a new office in the United Arab Emirates to join its locations in France, Singapore, and the United States.
Regulatory Readiness and Future Outlook:
Flowdesk is proactively gearing up for the European Union’s Markets in Crypto-Assets (MiCA) regime, keeping it well-placed to serve the changing crypto market in Europe. The company’s regulatory compliance is a testament to its vision to be a leader in the institutional crypto trading segment while being transparent and scalable.
With this new capital, Flowdesk will be accelerating its vision to bridge the old financial world and the fast-developing crypto economy, solidifying its position as a leading global digital asset player.
For more insights and updates on Metaverse, DeFi, Blockchain, NFT & Web3, be sure to subscribe to our newsletter. Stay informed on the latest trends and developments in the decentralized world!
What industry-specific factors are fueling the growth of the passenger vehicle telematics market?The surge in demand for passenger cars is anticipated to drive the expansion of the passenger vehicle telematics market. Passenger cars are vehicles engineered for human transport. In modern-day passenger cars, telematics technology is employed to boost vehicle performance, safety, and connectivity. It enhances security, upgrades comfort, curtails maintenance expenses, and provides speed monitoring and fleet management services. For example, as per the data disclosed by the Society of Motor Manufacturers and Traders (SMMT), a trade association from the UK, passenger car sales increased by 16.7% in 2023, reaching 145,204 units. Moreover, the European Automobile Manufacturers Association, a Belgium-based car association, reported that the European Union manufactured 10.9 million passenger cars in 2022, registering a growth of 8.3% from 2021. As a result, the escalating demand for passenger cars is fostering the expansion of the passenger vehicle telematics market.
Get Your Passenger Vehicle Telematics Market Report Here:https://www.thebusinessresearchcompany.com/report/passenger-vehicle-telematics-global-market-report
What Is the projected market size and growth rate for the passenger vehicle telematics market?Over the recent years, there has been substantial growth in the passenger vehicle telematics market size. With its worth expected to increase from $8.19 billion in 2024 to $9.16 billion in 2025, it shows a compound annual growth rate (CAGR) of 11.8%. Factors such as the shift towards digitalization, customer’s demand for connectivity, transformation of insurance models, decline in hardware and connectivity costs, and market rivalry and differentiation have all contributed to this historical growth.
In the coming years, the passenger vehicle telematics market is predicted to experience significant growth, with its market size anticipated to reach $14.98 billion by 2029 at a compound annual growth rate (CAGR) of 13.1%. Factors contributing to this growth include the use of telematics for managing traffic, an increased focus on cybersecurity, a move towards mobility-as-a-service (maas), greater incorporation of connected infotainment systems, and the integration of 5g technology. During the forecast period, key trends such as improved driver behavior analysis, the integration of vehicle-to-infrastructure (v2i) communication, the growth of over-the-air (OTA) updates, superior remote vehicle control, and the monetization of telematics data are also expected to be prominent.
Get Your Free Sample Now – Explore Exclusive Market Insights:https://www.thebusinessresearchcompany.com/sample.aspx?id=12365&type=smp
What are the emerging trends shaping the future of the passenger vehicle telematics market?Predominant corporations in the passenger vehicle telematics sector are prioritizing the creation of cutting-edge technological solutions like progressive collision prediction systems to improve safety and aid driver functionalities. An advanced collision prediction mechanism is a vehicular safety technology that utilizes data inputs from diverse sensors, cameras, radar, and GPS to predict possible collisions. For instance, Brigade Electronics Inc., a corporation based in the UK that offers vehicle safety solutions, unveiled Radar Predict in November 2023. This is a superior collision prediction system aimed at bolstering the safety of cyclists around heavy goods vehicles (HGVs). This pioneering technology acts like a Blind Spot Information System (BSIS), leveraging artificial intelligence to study vehicle trajectory, speed, and the proximity of incoming cyclists for collision prediction. With a dual-radar component for all-encompassing coverage, Radar Predict offers drivers escalating visual and auditory warnings contingent on the severity of the situation and automatically turns on during corners.
What major market segments define the scope and growth of the passenger vehicle telematics market?The passenger vehicle telematics market covered in this report is segmented –
1) By Type: Remote Message Processing System, Brake System, Transmission Control System, Navigation System, Infotainment System, Safety And Security System2) By Communication: Vehicle-To-Vehicle (V2V), Vehicle-To-Everything (V2X), Vehicle-To-Infrastructure (V2I), Vehicle-To-Pedestrian (V2P)3) By Application: Passenger Car, Light Commercial Vehicle, Heavy Commercial Vehicle
Subsegments:1) By Remote Message Processing System: Vehicle-To-Vehicle (V2V) Communication, Vehicle-To-Infrastructure (V2i) Communication2) By Brake System: Anti-Lock Braking Systems (ABs), Electronic Brakeforce Distribution (EBD), Emergency Brake Assist (EBA)3) By Transmission Control System: Automatic Transmission Control Modules (TCM), Continuously Variable Transmission (CVT) Controllers4) By Navigation System: GPs-based navigation, Real-Time Traffic Updates, Route Planning And Optimization5) By Infotainment System: Multimedia Systems (Audio, Video), Smartphone Integration (Apple Carplay, Android Auto), In-Car Internet Access6) By Safety And Security System: Emergency Call (Ecall) Systems, Theft Tracking And Immobilization, Advanced Driver-Assistance Systems (Adas)
Unlock Exclusive Market Insights – Purchase Your Research Report Now!https://www.thebusinessresearchcompany.com/purchaseoptions.aspx?id=12365
Which region dominates the passenger vehicle telematics market?North America was the largest region in the passenger vehicle telematics market in 2024. The regions covered in the passenger vehicle telematics market report are Asia-Pacific, Western Europe, Eastern Europe, North America, South America, Middle East, Africa
Which key market leaders are driving the passenger vehicle telematics industry growth?Major companies operating in the passenger vehicle telematics market include Verizon Communications Inc., AT&T Inc, Robert Bosch GmbH, Vodafone Group plc, Qualcomm Inc., Continental AG, Bridgestone Corp., Danaher Corp., Telefonaktiebolaget LM Ericsson, Valeo SA, Harman International Industries, Garmin Ltd., Delphi Technologies plc, Visteon Corp., Trimble Inc., Agero Inc., Omnitracs LLC., Telenav Inc., Fleet Complete, MiX Telematics, OCTO Telematics S.p.A, Masternaut Limited, Bynx Ltd., Airbiquity Inc., AirIQ Inc.
Customize Your Report – Get Tailored Market Insights!https://www.thebusinessresearchcompany.com/sample.aspx?id=12365&type=smp
What Is Covered In The Passenger Vehicle Telematics Global Market Report?
• Market Size Forecast: Examine the passenger vehicle telematics market size across key regions, countries, product categories, and applications.• Segmentation Insights: Identify and classify subsegments within the passenger vehicle telematics market for a structured understanding.• Key Players Overview: Analyze major players in the passenger vehicle telematics market, including their market value, share, and competitive positioning.• Growth Trends Exploration: Assess individual growth patterns and future opportunities in the passenger vehicle telematics market.• Segment Contributions: Evaluate how different segments drive overall growth in the passenger vehicle telematics market.• Growth Factors: Highlight key drivers and opportunities influencing the expansion of the passenger vehicle telematics market.• Industry Challenges: Identify potential risks and obstacles affecting the passenger vehicle telematics market.• Competitive Landscape: Review strategic developments in the passenger vehicle telematics market, including expansions, agreements, and new product launches.
Connect with us on:LinkedIn: https://in.linkedin.com/company/the-business-research-company,Twitter: https://twitter.com/tbrc_info,YouTube: https://www.youtube.com/channel/UC24_fI0rV8cR5DxlCpgmyFQ.
Learn More About The Business Research CompanyWith over 15,000+ reports from 27 industries covering 60+ geographies, The Business Research Company has built a reputation for offering comprehensive, data-rich research and insights. Our flagship product, the Global Market Model delivers comprehensive and updated forecasts to support informed decision-making.
This release was published on openPR.
About Web3Wire Web3Wire – Information, news, press releases, events and research articles about Web3, Metaverse, Blockchain, Artificial Intelligence, Cryptocurrencies, Decentralized Finance, NFTs and Gaming. Visit Web3Wire for Web3 News and Events, Block3Wire for the latest Blockchain news and Meta3Wire to stay updated with Metaverse News.
The following is a guest post by Tim Delhaes, CEO & Co-founder of Grindery.
The mood in crypto has shifted.
For some, it’s full-blown nihilism—Web3 has become a rigged casino, an insider’s game where those with the right connections print wealth at the expense of everyone else. The LIBRA scandal laid bare what many suspected but few could prove: a coordinated playbook where hype, exclusivity, and controlled liquidity create a mirage of opportunity, only for insiders to cash out at the peak, leaving retail investors with dust. The recent Bybit hack only reinforced the sense of disillusionment—security failures, insider games, and extractive behavior seem to define the space more than innovation ever did.
For others, this is the wake-up call we needed. The illusion has been shattered, but the mission remains. Now that the mechanics of these schemes are exposed, we have a choice: continue down the same road, rewarding short-term speculation, or take a hard look at the systems we are building and demand better.
The danger isn’t just regulation – it’s the return of centralized gatekeepers
While many are focused on the potential regulatory shifts— led by the prospect of looser enforcement and clearer industry-specific regulations in the U.S. — and the dream of another bull run, the real threat is already here.
Take Telegram. Long considered one of Web3’s most essential platforms, it has quietly pivoted to align with U.S. regulators and Big Tech players, enforcing monopolistic restrictions on blockchain development. This is a familiar playbook: Apple’s App Store 2.0, but for crypto. Controlling access, dictating which chains get visibility, and reshaping the ecosystem on their terms.
We’ve seen this before. Web2 was supposed to be open—until a handful of corporations consolidated power, built walled gardens, and turned the internet into a rent-seeking empire. And yet, instead of pushing back, much of Web3 remains distracted by the next fleeting hype cycle: memecoins, vaporware projects, and hamster-themed casino tokens.
Bitcoin’s origin wasn’t about convenience—it was about resistance. Web3 wasn’t supposed to replicate traditional finance; it was supposed to replace it with something better. But decentralization is hard, and without a clear commitment to its principles, we are watching the industry slip back into the hands of centralized players.
Regulation won’t save us, and it was never supposed to
Some argue that regulatory action could curb this trend, much like the EU forcing Apple to open up its payment systems. But counting on regulators to protect Web3 is a fool’s errand. Governments act in their own interests, and when crypto’s dominant narrative is speculation over substance, it’s not hard to see why policymakers view it as an industry worth containing rather than fostering.
The real question isn’t whether regulators will intervene. It’s whether Web3 can still prove it has a purpose beyond gambling.
The road ahead: stop rewarding empty hype
The solutions aren’t abstract, they’re actually structural. We know how this ends if we let monopolistic control go unchecked. We know that platforms with centralized gatekeepers will always prioritize profit over principles. We know that “security” and “user protection” are often just PR-friendly euphemisms for control.
And yet, instead of funding and building real alternatives, we’ve been handing the spotlight as well as liquidity to the same schemes that make Web3 look like a Ponzi playground instead of a real technological movement.
This isn’t just about ideology; it’s about survival. Censorship resistance, interoperability, and decentralized control aren’t just moral stances—they are Web3’s only real competitive advantages. The moment we start mimicking Web2’s monopolistic models, we lose everything that made crypto worth fighting for.
The path forward is clear: open systems, cross-chain accessibility, and ruthless resistance to centralized control. If Web3 continues to prioritize speculation over infrastructure, hype over substance, and quick flips over long-term innovation, we will have no one to blame for its downfall but ourselves.
In a significant advancement for the AI community, Spheron recently unveiled its DeepSeek-R1-Distill-Llama-70B Base model with BF16 precision—a development that promises to reshape how developers and researchers approach artificial intelligence applications. Despite their immense capabilities, base models have remained largely inaccessible to the broader tech community until now. Spheron’s latest offering provides unprecedented access to the raw power and creative potential that only base models can deliver, marking a crucial turning point in AI accessibility.
Understanding Base Models: The Unfiltered Powerhouses of AI
Base models represent the foundation of modern language AI—untamed, unfiltered systems containing the full spectrum of knowledge from their extensive training data. Unlike their instruction-tuned counterparts that have been optimized for specific tasks, base models maintain their original, unconstrained potential, making them extraordinarily versatile for developers seeking to build custom solutions from the ground up.
The significance of base models lies in their “uncollapsed” nature. When presented with a sequence of inputs, they can generate remarkably diverse variations for subsequent outputs with high entropy. This translates to significantly more creative and unpredictable results than instruction-tuned models designed to follow specific patterns and behaviors.
“Base models are like having a blank canvas with infinite possibilities,” explains Spheron in their recent announcement on X. “They retain more creativity and capabilities than instruction-tuned models, making them perfect for pushing AI boundaries.”
The BF16 Advantage: Balancing Performance and Precision
A critical innovation in Spheron’s offering is the implementation of the BF16 (bfloat16) floating-point format. This technical enhancement carefully calibrates the balance between processing speed and numerical precision, a crucial consideration when working with models containing hundreds of billions of parameters.
BF16 stands out as a floating-point format optimized explicitly for machine learning applications. By reducing the precision from 32 bits to 16 bits while maintaining the same exponent range as 32-bit formats, BF16 delivers substantial performance improvements without significantly compromising the model’s capabilities.
For developers working with massive AI systems, these efficiency gains translate to several tangible benefits:
Accelerated processing times: Operations complete more quickly, allowing for faster iteration and experimentation
Reduced memory requirements: The smaller data format means more efficient use of available hardware
Lower operational costs: Faster processing and reduced resource consumption lead to more economical deployment
Broader accessibility: The optimization makes powerful models viable on a wider range of hardware configurations
“When you’re running massive models, every millisecond counts,” notes Spheron. “BF16 lets you process information faster without sacrificing too much precision. It’s like having a sports car that’s also fuel-efficient!”
The Synergistic Power of Base Models and BF16
These two technological approaches—base models and BF16 precision—create a particularly powerful synergy. Developers gain access to both the unbounded creative potential of base models and the performance advantages of optimized numerical representation.
This combination enables a range of applications that might otherwise be impractical or impossible:
Development of highly customized language models tailored to specific domains
Exploration of novel AI capabilities without the constraints of instruction tuning
Efficient processing of massive datasets for training specialized models
Implementation of AI solutions in resource-constrained environments
Rapid prototyping and iteration of new AI concepts
Comparing Base Models to Instruction-Tuned Models
To fully appreciate the significance of Spheron’s offering, it’s helpful to understand the key differences between base models and their instruction-tuned counterparts:
FeatureBase ModelsInstruction-Tuned Models
Creative PotentialExtremely high with unpredictable outputsMore constrained and predictable
CustomizationHighly flexible for custom applicationsPre-optimized for specific tasks
Raw CapabilitiesUnfiltered, maintaining full training capabilitiesCapabilities potentially reduced during tuning
Development FlexibilityMaximum freedom for developersLimited by pre-existing optimizations
Output VarietyHigh entropy with diverse possibilitiesLower entropy with more consistent outputs
Learning CurveSteeper requires more expertise to optimizeEasier to use out-of-the-box
Resource RequirementsHigher when used without optimizationOften more efficient for specific tasks
BF16 BenefitSubstantial performance gains while preserving capabilitiesLess impactful as models are already optimized
The Future of AI Development with Spheron
Spheron’s commitment to democratizing access to powerful AI tools represents a significant step toward a more open and collaborative AI ecosystem. By providing developers with access to their 405B Base model in BF16 format, they’re enabling a new generation of AI innovations that might otherwise never emerge.
“The hype around base models is not false—real capabilities back it,” asserts Spheron. “Whether you’re a developer, researcher, or AI enthusiast, having access to base models with BF16 precision is like having a supercomputer in your toolkit!”
This initiative aligns with Spheron’s mission as “the leading open-access AI cloud, building an open ecosystem and economy for AI.” Founded by award-winning Math and AI researchers from prestigious institutions, Spheron envisions a future where AI technology is universally accessible, empowering individuals and communities worldwide.
Conclusion: A New Frontier in AI Development
For serious AI developers and researchers, Spheron’s release of their 405B Base model with BF16 precision represents a significant opportunity to explore the boundaries of what’s possible with current technology. Combining unrestricted base model capabilities and optimized performance creates a powerful foundation for the next generation of AI applications.
As the technology continues to mature and more developers gain access to these tools, we can expect to see increasingly innovative applications emerge across industries. The democratization of high-performance AI models promises to accelerate the pace of innovation and potentially lead to breakthroughs that might otherwise remain undiscovered.
Those interested in exploring these capabilities can access Spheron’s platform through their console at console.spheron.network, joining a growing community of innovators pushing the boundaries of artificial intelligence.
Dogecoin (DOGE), Ethereum (ETH), and Solana (SOL) have all recorded double-digit declines in the past 24 hours, following surges after U.S. President Donald Trump announced a federal crypto reserve last Friday.
ETH is down 11.4% in the past 24 hours and down 13.9% week over week, according to CoinGecko, despite Trump saying it is set to be included in the U.S. crypto reserve in a post on Truth Social. It dropped to $2,035, its lowest level since November 2023, while its price ratio versus Bitcoin reached a historic low last month.
SOL fell 16.1% over the past 24 hours and is down 2.9% on the week, following Trump’s crypto reserve announcement. It’s trading at its lowest price since early September 2024, after hitting another three-month low just weeks ago, amid skepticism about the future of Solana-based meme coins.
Meanwhile, DOGE recorded losses of 12.4% in the past 24 hours and 6.6% week over week. It’s hovering at its lowest level since early November 2024. Despite not being named in Trump’s crypto reserve plans, it still spiked alongside the rest of the crypto market’s post-announcement surge.
Dr. Sean Dawson, head of research at options platform Derive.xyz, thinks the rapid price declines could be due to uncertainty around the details of Trump’s reserve plans.
“This market behavior highlights that while announcements like Trump’s strategic reserve can spark short-term excitement, the lack of clarity and follow-through can lead to rapid corrections,” Dawson said. He added that, “Volatility will likely remain high as traders navigate the uncertain year ahead.”
He pointed to the fact that high-profile figures from the crypto industry have criticized the inclusion of non-Bitcoin digital assets in the strategic reserve, among them Gemini co-founders Cameron and Tyler Winklevoss and Coinbase CEO Brian Armstrong. Investment firm Bernstein has also been skeptical of the move.
Cameron Winklevoss recently tweeted that “Bitcoin is the only asset that meets the bar for a store of value reserve asset,” adding, “Maybe Ethereum.”
Valentin Fournier, analyst at crypto research firm BRN, attributed the harsh declines to “Trump’s confirmation that 25% tariffs on Mexico and Canada will take effect on March 4th” which he said are “injecting uncertainty into the market” and creating a “risk-off sentiment.”
The total market cap of all cryptocurrencies is down 10.7%, according to CoinGecko. But it’s not just cryptocurrencies that have recorded poor performances in recent months; stocks are down across the board, particularly in the tech sector ahead of Trump’s tariffs.
The Nasdaq is down 2.64% at the time of writing, while the S&P 500 is down 1.76%, per data from Yahoo Finance.
Crypto research group QCP also highlighted other macroeconomic factors as being behind the crypto market’s price correction, such as falling yields of 10-year U.S. Treasury bills.
Daily Debrief Newsletter
Start every day with the top news stories right now, plus original features, a podcast, videos and more.
Web3 backend development is essential for building scalable, efficient and decentralized applications (dApps) on EVM-compatible blockchains like Ethereum, Polygon, and Base. A robust Web3 backend enables off-chain computations, efficient data management and better security, ensuring seamless interaction between smart contracts, databases and frontend applications.
Unlike traditional Web2 applications that rely entirely on centralized servers, Web3 applications aim to minimize reliance on centralized entities. However, full decentralization isn’t always possible or practical, especially when it comes to high-performance requirements, user authentication or storing large datasets. A well-structured backend in Web3 ensures that these limitations are addressed, allowing for a seamless user experience while maintaining decentralization where it matters most.
Furthermore, dApps require efficient backend solutions to handle real-time data processing, reduce latency, and provide smooth user interactions. Without a well-integrated backend, users may experience delays in transactions, inconsistencies in data retrieval, and inefficiencies in accessing decentralized services. Consequently, Web3 backend development is a crucial component in ensuring a balance between decentralization, security, and functionality.
This article explores:
When and why Web3 dApps need a backend
Why not all applications should be fully on-chain
Architecture examples of hybrid dApps
A comparison between APIs and blockchain-based logic
This post kicks off a Web3 backend development series, where we focus on the technical aspects of implementing Web3 backend solutions for decentralized applications.
Why Do Some Web3 Projects Need a Backend?
Web3 applications seek to achieve decentralization, but real-world constraints often necessitate hybrid architectures that include both on-chain and off-chain components. While decentralized smart contracts provide trustless execution, they come with significant limitations, such as high gas fees, slow transaction finality, and the inability to store large amounts of data. A backend helps address these challenges by handling logic and data management more efficiently while still ensuring that core transactions remain secure and verifiable on-chain.
Moreover, Web3 applications must consider user experience. Fully decentralized applications often struggle with slow transaction speeds, which can negatively impact usability. A hybrid backend allows for pre-processing operations off-chain while committing final results to the blockchain. This ensures that users experience fast and responsive interactions without compromising security and transparency.
While decentralization is a core principle of blockchain technology, many dApps still rely on a Web2-style backend for practical reasons:
1. Performance & Scalability in Web3 Backend Development
Smart contracts are expensive to execute and require gas fees for every interaction.
Offloading non-essential computations to a backend reduces costs and improves performance.
Caching and load balancing mechanisms in traditional backends ensure smooth dApp performance and improve response times for dApp users.
Event-driven architectures using tools like Redis or Kafka can help manage asynchronous data processing efficiently.
2. Web3 APIs for Data Storage and Off-Chain Access
Storing large amounts of data on-chain is impractical due to high costs.
APIs allow dApps to store & fetch off-chain data (e.g. user profiles, transaction history).
Decentralized storage solutions like IPFS, Arweave and Filecoin can be used for storing immutable data (e.g. NFT metadata), but a Web2 backend helps with indexing and querying structured data efficiently.
3. Advanced Logic & Data Aggregation in Web3 Backend
Some dApps need complex business logic that is inefficient or impossible to implement in a smart contract.
Backend APIs allow for data aggregation from multiple sources, including oracles (e.g. Chainlink) and off-chain databases.
Middleware solutions like The Graph help in indexing blockchain data efficiently, reducing the need for on-chain computation.
4. User Authentication & Role Management in Web3 dApps
Many applications require user logins, permissions or KYC compliance.
Blockchain does not natively support session-based authentication, requiring a backend for handling this logic.
Tools like Firebase Auth, Auth0 or Web3Auth can be used to integrate seamless authentication for Web3 applications.
5. Cost Optimization with Web3 APIs
Every change in a smart contract requires a new audit, costing tens of thousands of dollars.
By handling logic off-chain where possible, projects can minimize expensive redeployments.
Using layer 2 solutions like Optimism, Arbitrum and zkSync can significantly reduce gas costs.
Web3 Backend Development: Tools and Technologies
A modern Web3 backend integrates multiple tools to handle smart contract interactions, data storage, and security. Understanding these tools is crucial to developing a scalable and efficient backend for dApps. Without the right stack, developers may face inefficiencies, security risks, and scaling challenges that limit the adoption of their Web3 applications.
Building a Web3 backend requires integrating various technologies to handle blockchain interactions, data storage, and security. Unlike traditional backend development, Web3 requires additional considerations, such as decentralized authentication, smart contract integration, and secure data management across both on-chain and off-chain environments.
Here’s an overview of the essential Web3 backend tech stack:
1. API Development for Web3 Backend Services
Node.js is the go-to backend runtime good for Web3 applications due to its asynchronous event-driven architecture.
NestJS is a framework built on top of Node.js, providing modular architecture and TypeScript support for structured backend development.
2. Smart Contract Interaction Libraries for Web3 Backend
Ethers.js and Web3.js are TypeScript/JavaScript libraries used for interacting with Ethereum-compatible blockchains.
3. Database Solutions for Web3 Backend
PostgreSQL: Structured database used for storing off-chain transactional data.
MongoDB: NoSQL database for flexible schema data storage.
Firebase: Cloud database commonly used for storing authentication records.
The Graph: Decentralized indexing protocol used to query blockchain data efficiently.
4. Cloud Services and Hosting for Web3 APIs
When It Doesn’t Make Sense to Go Fully On-Chain
Decentralization is valuable, but it comes at a cost. Fully on-chain applications suffer from performance limitations, high costs and slow execution speeds. For many use cases, a hybrid Web3 architecture that utilizes a mix of blockchain-based and off-chain components provides a more scalable and cost-effective solution.
In some cases, forcing full decentralization is unnecessary and inefficient. A hybrid Web3 architecture balances decentralization and practicality by allowing non-essential logic and data storage to be handled off-chain while maintaining trustless and verifiable interactions on-chain.
The key challenge when designing a hybrid Web3 backend is ensuring that off-chain computations remain auditable and transparent. This can be achieved through cryptographic proofs, hash commitments and off-chain data attestations that anchor trust into the blockchain while improving efficiency.
For example, Optimistic Rollups and ZK-Rollups allow computations to happen off-chain while only submitting finalized data to Ethereum, reducing fees and increasing throughput. Similarly, state channels enable fast, low-cost transactions that only require occasional settlement on-chain.
A well-balanced Web3 backend architecture ensures that critical dApp functionalities remain decentralized while offloading resource-intensive tasks to off-chain systems. This makes applications cheaper, faster and more user-friendly while still adhering to blockchain’s principles of transparency and security.
Example: NFT-based Game with Off-Chain Logic
Imagine a Web3 game where users buy, trade and battle NFT-based characters. While asset ownership should be on-chain, other elements like:
Game logic (e.g., matchmaking, leaderboard calculations)
User profiles & stats
Off-chain notifications
can be handled off-chain to improve speed and cost-effectiveness.
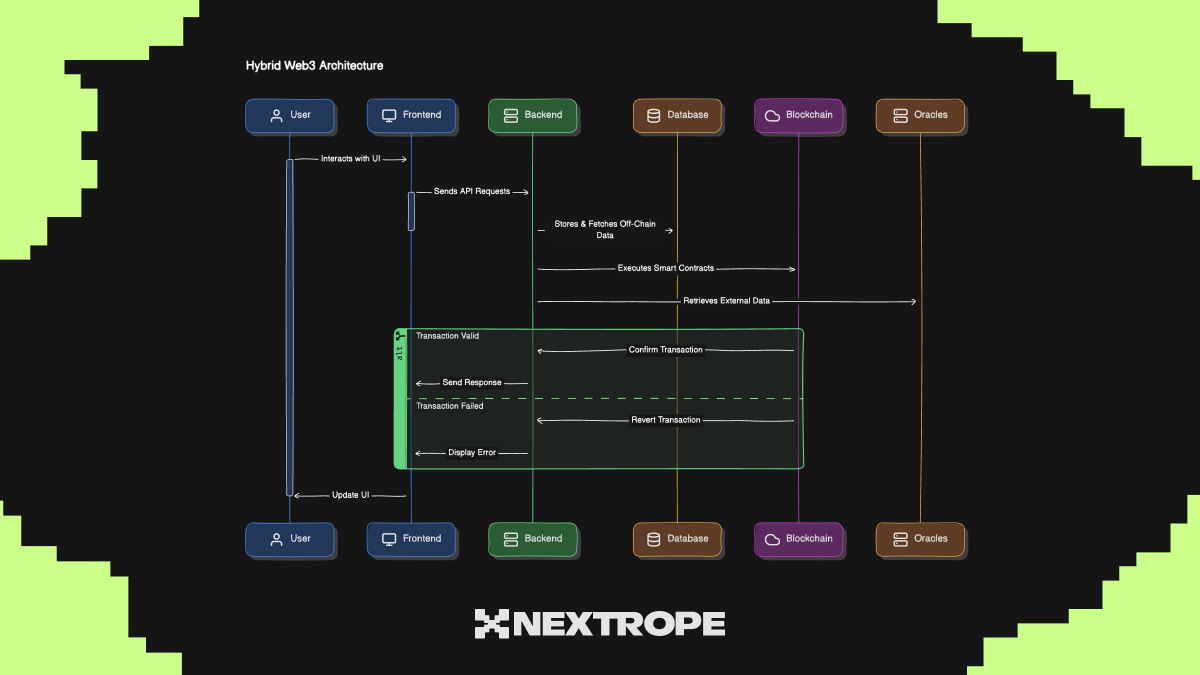
Architecture Diagram
Below is an example diagram showing how a hybrid Web3 application splits responsibilities between backend and blockchain components.
Comparing Web3 Backend APIs vs. Blockchain-Based Logic
FeatureWeb3 Backend (API)Blockchain (Smart Contracts)Change ManagementCan be updated easilyEvery change requires a new contract deploymentCostTraditional hosting feesHigh gas fees + costly auditsData StorageCan store large datasetsLimited and expensive storageSecuritySecure but relies on centralized infrastructureFully decentralized & trustlessPerformanceFast response timesLimited by blockchain throughput
Reducing Web3 Costs with AI Smart Contract Audit
One of the biggest pain points in Web3 development is the cost of smart contract audits. Each change to the contract code requires a new audit, often costing tens of thousands of dollars.
To address this issue, Nextrope is developing an AI-powered smart contract auditing tool, which:
Reduces audit costs by automating code analysis.
Speeds up development cycles by catching vulnerabilities early.
Improves security by providing quick feedback.
This AI-powered solution will be a game-changer for the industry, making smart contract development more cost-effective and accessible.
Conclusion
Web3 backend development plays a crucial role in scalable and efficient dApps. While full decentralization is ideal in some cases, many projects benefit from a hybrid architecture, where off-chain components optimize performance, reduce costs and improve user experience.
In future posts in this Web3 backend series, we’ll explore specific implementation details, including:
Endless Web3 Genesis Cloud, a leading distributed intelligent component protocol, has successfully raised $110 million in a funding round that values the company at $1 billion. This significant milestone was backed by prominent investors, including Foresight Ventures. The newly acquired capital will be used to drive the development of Endless’ componentized development platform, AI Agent toolchain, and broader ecosystem expansion. Key focus areas for investment include product research and development, ecosystem support, long-term strategic reserves, and strong market partnerships. Endless is positioning itself as a transformative “super connector,” seamlessly bridging Web2 and Web3 while integrating AI with Web3 technologies.
Revolutionizing Web3 Development:
As a distributed intelligent component protocol, Endless is dedicated to reducing the barriers for Web2 applications to transition into Web3. The platform offers a comprehensive, one-stop solution for Web3 application development while ensuring a user experience comparable to Web2. By leveraging the Move programming language on its public blockchain, Endless integrates a variety of AI capabilities and plugins to create a frictionless development environment. This approach enables developers to build Crypto AI applications efficiently and at scale, paving the way for the emergence of the AI Agentic Super Intelligent System.
Backed by Industry Leaders:
Endless has garnered support from investors spanning Web3, the Internet, and financial sectors, bringing a wealth of industry expertise to the project. These strategic backers will play an instrumental role in Endless’ governance, ecosystem expansion, and overall strategic direction. Their contributions will help accelerate the mass adoption of Web3 and advance the vision of an AI-powered intelligent ecosystem.
Leadership with Deep Expertise in AI and Web3:
The leadership team behind Endless boasts extensive experience in both AI and Web3 technologies, positioning the company as a key player in the industry’s future.
Xiong Yu, Co-President: Serving as Associate Vice-President at the University of Surrey, Xiong also leads the Institute of Blockchain and Artificial Intelligence. His research in AI and blockchain has been instrumental in developing efficient large language models and real-time AI-generated imaging. Additionally, he has held visiting positions at esteemed institutions such as Cambridge and Oxford.
Amit Kumar Jaiswal, Chief Technology Officer: An academic chair at the Indian Institute of Technology’s School of Computer Science, Amit is also a researcher at the University of Surrey. He specializes in machine learning, generative AI, decentralized finance (DeFi), and Web3. Previously, he co-founded Quanonblocks LLP and served as its Chief Technology Officer.
Ned, Chief Token Economist: With more than a decade of experience in quantitative finance and blockchain, Ned has worked on pioneering projects in DeFi, blockchain infrastructure, and Web3 innovation. His research at Oxford and Cambridge has focused on distributed systems and token economics, contributing to groundbreaking advancements in the space.
Shaping the Future of AI and Web3:
Endless’s ambitious roadmap and experienced leadership position it as a game-changer in the AI and Web3 landscape. By providing a seamless integration of AI-driven solutions into Web3, the company aims to redefine how developers and users interact with blockchain technology.
About Endless Web3 Genesis Cloud:
Endless Web3 Genesis Cloud is a cutting-edge distributed intelligent component protocol that simplifies the transition from Web2 to Web3 for developers. With a powerful blockchain infrastructure built on the Move language, Endless integrates AI capabilities and plugins to create the best possible bridge between AI and Crypto. The platform empowers developers to create next-generation Crypto AI applications using a componentized framework, accelerating the arrival of the AI Agentic Super Intelligent System.
With its recent $110M funding round, Endless is well on its way to becoming the leading force in AI-Web3 integration, unlocking new possibilities for innovation in the digital ecosystem.
For more insights and updates on Metaverse, DeFi, Blockchain, NFT & Web3, be sure to subscribe to our newsletter. Stay informed on the latest trends and developments in the decentralized world!
Latest Study on Growth of AI Optimization and Orchestration Market 2024-2031. A detailed study was accumulated to offer the latest insights about the acute features of the AI optimization and orchestration market. The report contains different market predictions related to revenue size, production, CAGR, Consumption, gross margin, price, and other substantial factors.
According to HTF MI, the AI Optimization and Orchestration Market is estimated to reach USD 44 Billion by 2031, currently pegged at USD 12.8 Billion. In 2020 the market size was ~ USD 3.9 Billion since then a growth rate of 28 % was witnessed in the market.
The Major Players Covered in this Report: VMware, Cisco, IBM, Red Hat, Microsoft, Datadog, Splunk, ServiceNow, Oracle, BMC Software, CloudBolt, Turbonomic, Trend Micro, AppDynamics, NetApp, Elastic, Dynatrace, Nagios
Get Access to Statistical Data, Charts & Key Players’ Strategies https://www.htfmarketreport.com/sample-report/4344706-global-ai-optimization-and-orchestration-market-growth?utm_source=Krati_OpenPR&utm_id=Krati
Definition:AI optimization and orchestration involves the use of artificial intelligence to manage and optimize IT infrastructure and business processes. It integrates AI with traditional orchestration frameworks to automate decision-making, optimize resources, and improve operational efficiency. AI-based orchestration enables businesses to run multi-cloud environments efficiently, enhancing performance and minimizing downtime by predicting resource demands, automating tasks, and providing real-time insights.
Market DynamicsMarket Trends:Emergence of AI-driven orchestration, autonomous systems, real-time decision-making
Market Drivers:Rising demand for intelligent IT management, multi-cloud environments, and automation
Market Challenges:Integration complexity, scaling challenges, need for cross-platform compatibility
Read Detailed Index of full Research Study at https://www.htfmarketreport.com/reports/4344706-global-ai-optimization-and-orchestration-market-growth
The titled segments and sub-sections of the market are illuminated below:In-depth analysis of AI Optimization and Orchestration market segments by Types: Cloud-based, IT Automation, Orchestration, Machine Learning-based, HybridDetailed analysis of AI Optimization and Orchestration market segments by Applications: IT Operations, Cloud Infrastructure, Network Management, Real-time Monitoring, Business Process Automation
Regional Analysis of AI Optimization and Orchestration Market:By region, North America has shown clear dominance in AI Optimization and Orchestration market sizing, and the APAC region has witnessed the fastest growth and will continue at the same pace till 2031.
Furthermore, the years considered for the study are as follows:Historical year – 2020-2024Base year – 2024Forecast period** – 2024 to 2031 [** unless otherwise stated]
**Moreover, it will also include the opportunities available in micro markets for stakeholders to invest, a detailed analysis of the competitive landscape, and product services of key players.
Key takeaways from the AI Optimization and Orchestration market report:– Detailed consideration of AI Optimization and Orchestration market particular drivers, Trends, constraints, Restraints, Opportunities, and major micro markets.– Comprehensive valuation of all prospects and threats in the– In-depth study of industry strategies for growth of the AI Optimization and Orchestration market-leading players.– AI Optimization and Orchestration market latest innovations and major procedures.– Favorable dip inside Vigorous high-tech and market latest trends remarkable the Market.– Conclusive study about the growth conspiracy of the AI Optimization and Orchestration market for forthcoming years.
What to Expect from this Report On AI Optimization and Orchestration Market:1. A comprehensive summary of several area distributions and the summary types of popular products in the AI Optimization and Orchestration Market.2. You can fix up the growing databases for your industry when you have info on the cost of the production, cost of the products, and cost of the production for the next years.3. Thorough Evaluation of the break-in for new companies who want to enter the AI Optimization and Orchestration Market.4. Exactly how do the most important companies and mid-level companies make income within the Market?5. Complete research on the overall development within the AI Optimization and Orchestration Market that helps you select the product launch and overhaul growths.
Reach Our Experts For Any Question https://www.htfmarketreport.com/enquiry-before-buy/4344706-global-ai-optimization-and-orchestration-market-growth?utm_source=Krati_OpenPR&utm_id=Krati
Detailed TOC of AI Optimization and Orchestration Market Research Report-– AI Optimization and Orchestration Introduction and Market Overview– AI Optimization and Orchestration Market, by Application [IT Operations, Cloud Infrastructure, Network Management, Real-time Monitoring, Business Process Automation]– AI Optimization and Orchestration Industry Chain Analysis– AI Optimization and Orchestration Market, by Type [Cloud-based, IT Automation, Orchestration, Machine Learning-based, Hybrid]– Industry Manufacture, Consumption, Export, Import by Regions (2020-2023E)– Industry Value ($) by Region (2020-2023E)– AI Optimization and Orchestration Market Status and SWOT Analysis by Regions
– Major Region of AI Optimization and Orchestration Marketi) AI Optimization and Orchestration Salesii) AI Optimization and Orchestration Revenue & market share– Major Companies List– Conclusion
Thanks for reading this article; you can also get individual chapter-wise sections or region-wise report versions like North America, MINT, BRICS, G7, Western / Eastern Europe, or Southeast Asia. Also, we can serve you with customized research services as HTF MI holds a database repository that includes public organizations and Millions of Privately held companies with expertise across various Industry domains.
About Author:HTF Market Intelligence Consulting is uniquely positioned to empower and inspire with research and consulting services to empower businesses with growth strategies, by offering services with extraordinary depth and breadth of thought leadership, research, tools, events, and experience that assist in decision-making.
This release was published on openPR.
About Web3Wire Web3Wire – Information, news, press releases, events and research articles about Web3, Metaverse, Blockchain, Artificial Intelligence, Cryptocurrencies, Decentralized Finance, NFTs and Gaming. Visit Web3Wire for Web3 News and Events, Block3Wire for the latest Blockchain news and Meta3Wire to stay updated with Metaverse News.
Disclosure: This is a sponsored post. Readers should conduct further research prior to taking any actions. Learn more ›
Geneva, Switzerland , March 3 2025 – TRON DAO made its way to ETH Denver 2025, one of the most talked about blockchain conferences in the industry. While attending ETH Denver, TRON DAO came in as a Golden Sponsor for the highly anticipated CUBE Summit.The CUBE Summit, led by BuidlerDAO —short for the Collaborative University Blockchain Ecosystem Summit—marked the first-ever collaboration among twelve distinguished university blockchain clubs, including Cambridge, Columbia, Cornell, Harvard, MIT, NYU, Oxford, Princeton, Stanford, UC Berkeley, UPenn, and Yale. The CUBE summit aims to cultivate emerging talent and foster innovative projects, paving the way for the next generation of crypto leaders.
Day 2 of ETH Denver started off with Sam Elfarra, Community Spokesperson of TRON DAO engaging in a keynote session with a packed crowd, holding discussions around stablecoins and payments, showcasing the growing interest in blockchain-based financial solutions. Elfarra was also a judge for CUBE Summit’s Pitch Sessions — a platform for innovative projects to be built, showcased and pitched. Elfarra also presented a TRON award for the most outstanding project pitched that evening. Accelerating groundbreaking ideas that have the potential to shape the future of decentralized finance and Web3 applications.
TRON DAO also co-hosted CUBE Talent Night alongside BuidlerDAO and Blockchain at Berkeley which was held on 28th February. The networking session started off with a short welcome speech from TRON DAO touching on the latest updates happening on TRON, DeFi, and the broader Web3 ecosystem. TRON DAO’s participation highlighted its mission to empower a decentralized internet and promote real-world blockchain adoption to the next generation of rising talents.
“ETH Denver represented a hub for blockchain innovation, and TRON DAO was excited to be part of this gathering of bright minds and cutting-edge projects,” said Sam Elfarra, Community Spokesperson at TRON DAO. “Through our participation with the community over at CUBE Talent Night, we hope to have provided valuable insights and opportunities for developers and entrepreneurs who are shaping the future of the Web3 ecosystem. Let’s continue to build.”ETH Denver was the second major conference since the launch of TRON Builders League (TBL) that happened on February 19, 2025. This incubator program is designed to empower blockchain developers which offers mentorship, ecosystem integration and a funding pool of up to $10 million that has caught the eyes of many. TBL provides high-potential projects with the sustained support they need within the TRON ecosystem. For more information, visit TRON Builders League’s official page.
TRON DAO’s participation at ETH Denver and the sponsorship of the CUBE Summit highlights its continued support for blockchain innovation which ties in well with the mission of TRON Builders League. All in efforts to foster talent and drive the next wave of Web3 development.
About TRON DAO
TRON DAO is a community-governed DAO dedicated to accelerating the decentralization of the internet via blockchain technology and dApps.
Founded in September 2017 by H.E. Justin Sun, the TRON blockchain has experienced significant growth since its MainNet launch in May 2018. Until recently, TRON hosted the largest circulating supply of USD Tether (USDT) stablecoin, exceeding $60 billion. As of March 2025, the TRON blockchain has recorded over 290 million in total user accounts, more than 9.6 billion in total transactions, and over $21 billion in total value locked (TVL), based on TRONSCAN.
Long-standing art-focused NFT marketplace MakersPlace has abruptly announced its immediate closure, drawing its 6-year history to a close.In a statement, Brady Evan Walker,...