
Spheron is a decentralized supercompute platform that simplifies how developers and businesses use compute resources. Many people see it as a tool for both AI and Web3 projects, but there is more to it than that. It brings together different types of hardware in one place, so you do not have to juggle multiple accounts or pricing plans.
Spheron lets you pick from high-end machines that can train large AI models, as well as lower-tier machines that can handle everyday tasks, like testing or proof-of-concept work and deploying SLMs or AI agents. This balanced approach can save time and money, especially for smaller teams that do not need the most expensive GPU every time they run an experiment. Instead of making big claims about market sizes, Spheron focuses on the direct needs of people who want to build smart, efficient, and flexible projects.
Simplifying Infrastructure Management
One reason to look at Spheron is that it strips away the complexity of dealing with different providers. If you decide to host a project in the cloud, you often end up navigating a maze of services, billing structures, and endless documentation. That can slow down development and force you to spend energy on system admin work instead of your core product. Spheron reduces that friction. It acts like a single portal where you see your available compute options at a glance. You can filter by cost, power, or any other preference. You can select top-notch hardware for certain tasks and then switch to more modest machines when you want to save money. This helps you avoid the waste that happens when you reserve a large machine but only need a fraction of its power.
Blending AI and Web3 Support
Spheron merges AI and Web3 by offering a decentralized compute platform that meets the needs of both communities. AI developers rely on GPUs to handle large-scale computations with speed and efficiency, often working with massive datasets that demand parallel processing. Web3 developers care about smart contracts, blockchain-based tools, and transparent workloads. Spheron unites these requirements by letting them run advanced computations in one consistent environment. You can focus on your code, data, and results without juggling separate platforms. By bridging both AI and Web3 in a single place, Spheron delivers a cohesive experience that removes the walls between traditional computing infrastructures and decentralized solutions.
Resource Flexibility
Flexibility is another key point. Technology changes fast. New AI libraries emerge, and new Web3 protocols rise. Buying your own hardware can seem risky if you worry it will become outdated soon. Spheron lowers that risk by letting you move to new machines as soon as they come to market. You just check the platform, see what offerings are available, and switch if you want. This helps you stay current without taking on big capital expenses. When you need extra power—maybe to run a special training job—you can scale up. When that job ends, you can scale down. This elasticity is a hallmark of cloud computing, but Spheron takes it further by pooling resources from different places worldwide, not just a single data center.
Fizz Node: Powering Decentralized Compute at Scale
Fizz Node is a cornerstone of the Spheron platform, designed to distribute compute power efficiently across a decentralized network. Fizz Node combines decentralized principles with practical usability. It eliminates the inefficiencies of traditional cloud services by allowing users to scale their deployments globally without being tied to a single data center. This approach not only reduces costs but also provides redundancy and reliability, ensuring uninterrupted access to resources.
The platform has seen remarkable growth, with over 30,747 active nodes worldwide as of the most recent update. This global expansion is fueled by its ability to aggregate resources from diverse sources, offering flexibility and reliability for developers.
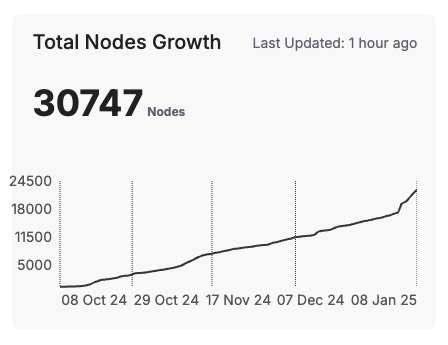
The current Fizz Node network has:
10,000 GPUs
303,300 CPU
15,400 Mac chips
762.62 TB of RAM
8.07 PB of storage
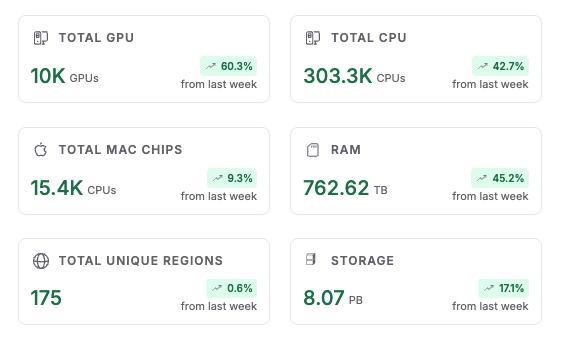
These numbers highlight the platform’s scalability and ability to support high-performance computing needs, whether for AI workloads or Web3 applications. The network spans 175 unique regions, further emphasizing its global reach and reliability.
Access to a Wide Range of AI Models
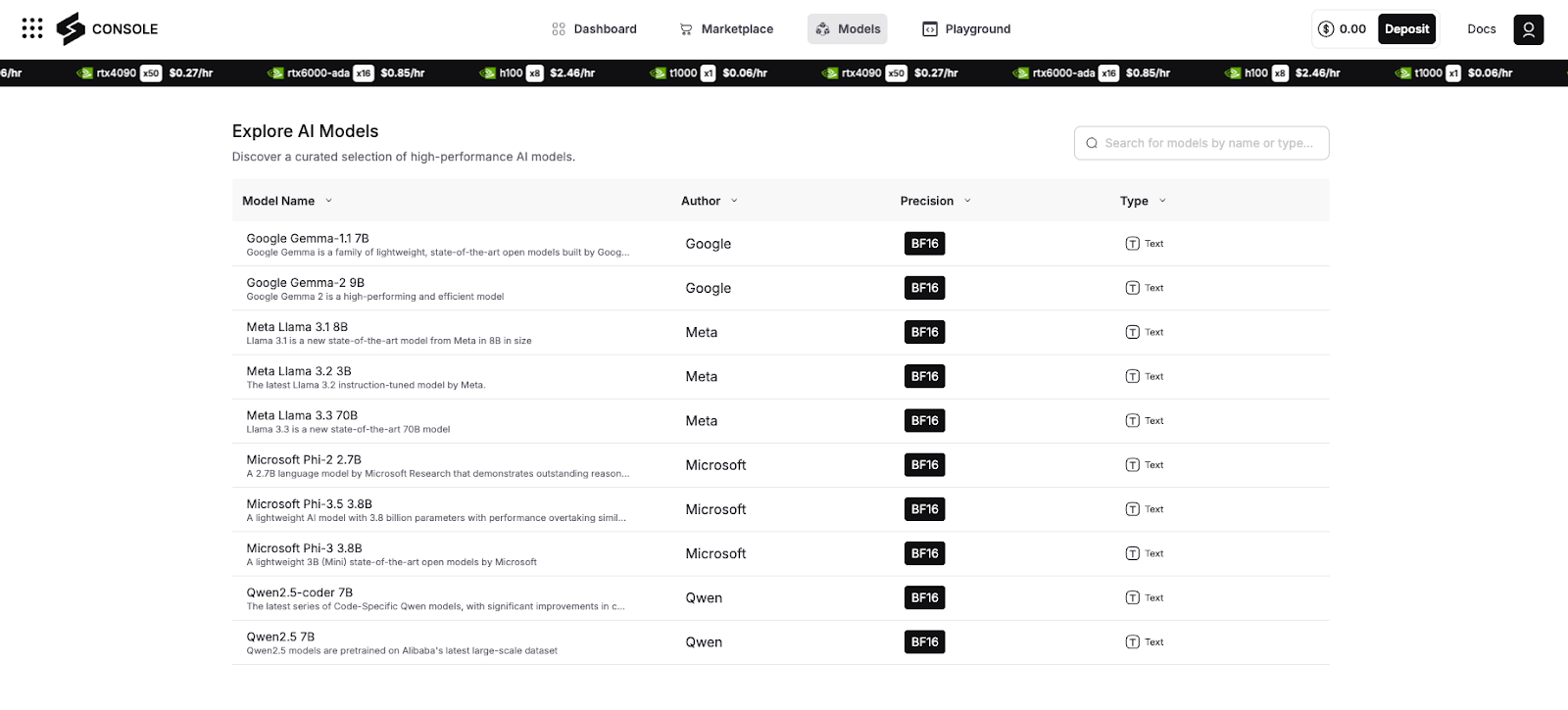
Spheron offers access to a curated list of AI models to suit different needs. These models include lightweight options like Google Gemma-1.1 (7B) and advanced ones like Meta Llama 3.3 (70B). Some models, like Qwen2.5-coder, are designed for specific tasks such as coding. All models use BF16 precision, which ensures efficient and reliable performance for both small and large computations. This variety allows you to choose the right model for your task, whether you’re building an AI agent, training a model, or running a proof-of-concept.
The platform makes it easy to explore these models, showing all the relevant details in a simple interface. This transparency helps you make informed decisions without wasting time. Whether you’re new to AI or an expert, you’ll find tools that match your skill level and project requirements.
Ease of Use
Ease of use stands out as one of Spheron’s core strengths. The platform removes barriers so you can focus on building and running your AI Agents rather than wrestling with complex technical overhead. Its interface makes it straightforward to pick the hardware you need, monitor your costs, and fine-tune your environment. If you’re new, you can follow a simple setup process. If you’re an expert, you can dive into deeper configuration details. You deal with only one tool instead of juggling various systems.
Spheron also offers a built-in Playground that guides you step-by-step:
Enter your deployment configuration in YAML. Spheron follows a standard format, so you can define your resources cleanly.
Obtain test ETH. Make sure you have enough test ETH in your wallet to cover deployment. You can use a faucet or Arbitrum Sepolia ETH and bridge it to the Spheron Chain. This funds your testing and registration.
Explore provider options. Visit provider.spheron.network or fizz.spheron.network to see available GPUs and regions.
Click “Start Deployment.” Once you finalize your setup, launch your AI Agents and view logs or errors in real time.
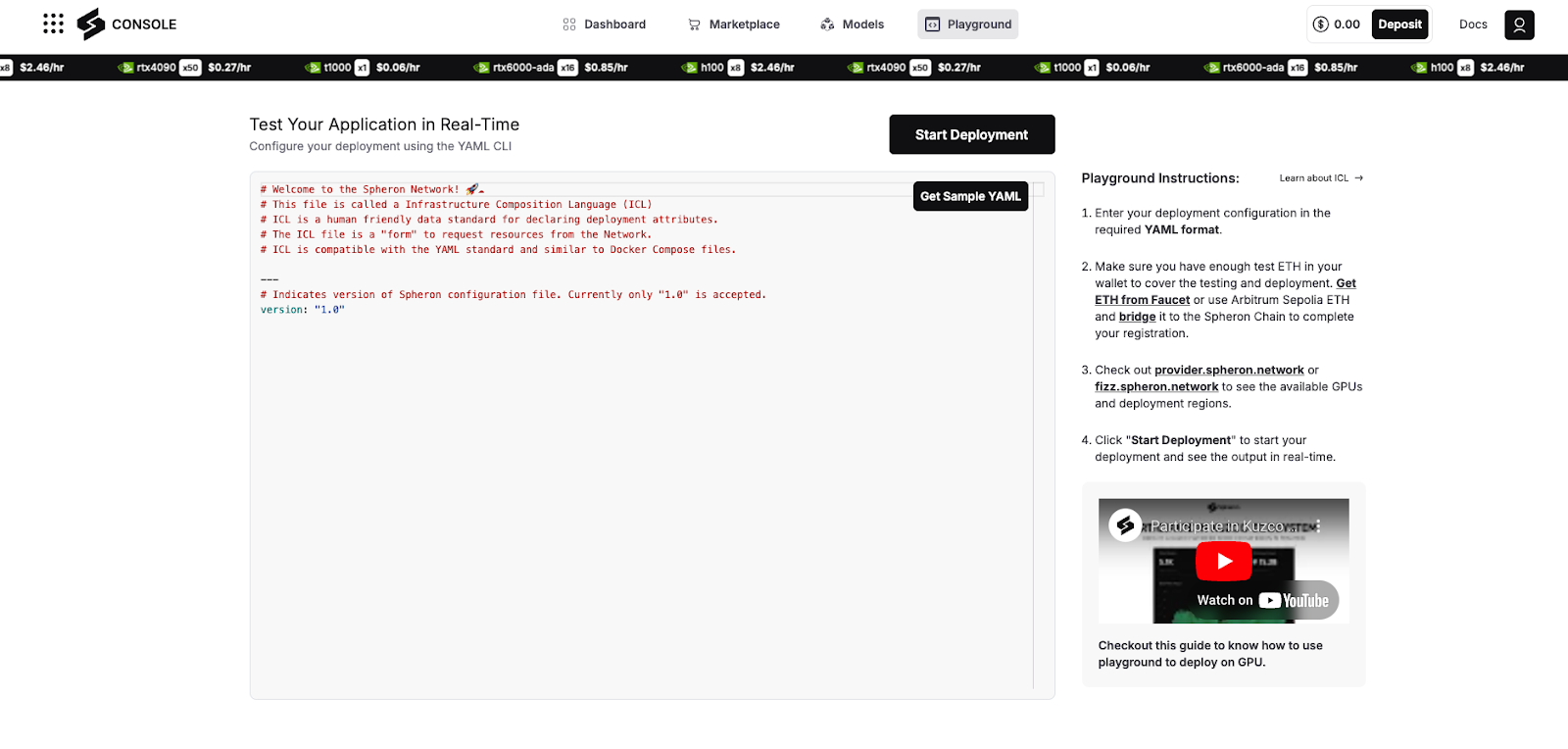
These steps show how simple it is to build and run AI Agents on Spheron. You skip the guesswork of configuring multiple platforms and gain a smooth path from setup to execution. The result is a user-friendly environment where you control costs, scale on demand, and bring your AI projects to life with minimal friction.
The Aggregator Advantage
The aggregator model drives many of these benefits. Spheron keeps a broad catalog of GPU types, memory sizes, and performance tiers by pooling machines from various sources. That means you can compare prices in real time and pick the hardware that works for you. Because multiple providers compete, you see fair pricing. Providers with idle resources can lower their rates to attract more users, which lowers your costs. If you have a specific GPU in mind, you can search for that. If you only care about cost, you can sort from cheapest to most expensive. This transparency is rare in single-cloud setups, where you might have only a handful of preset instance types.
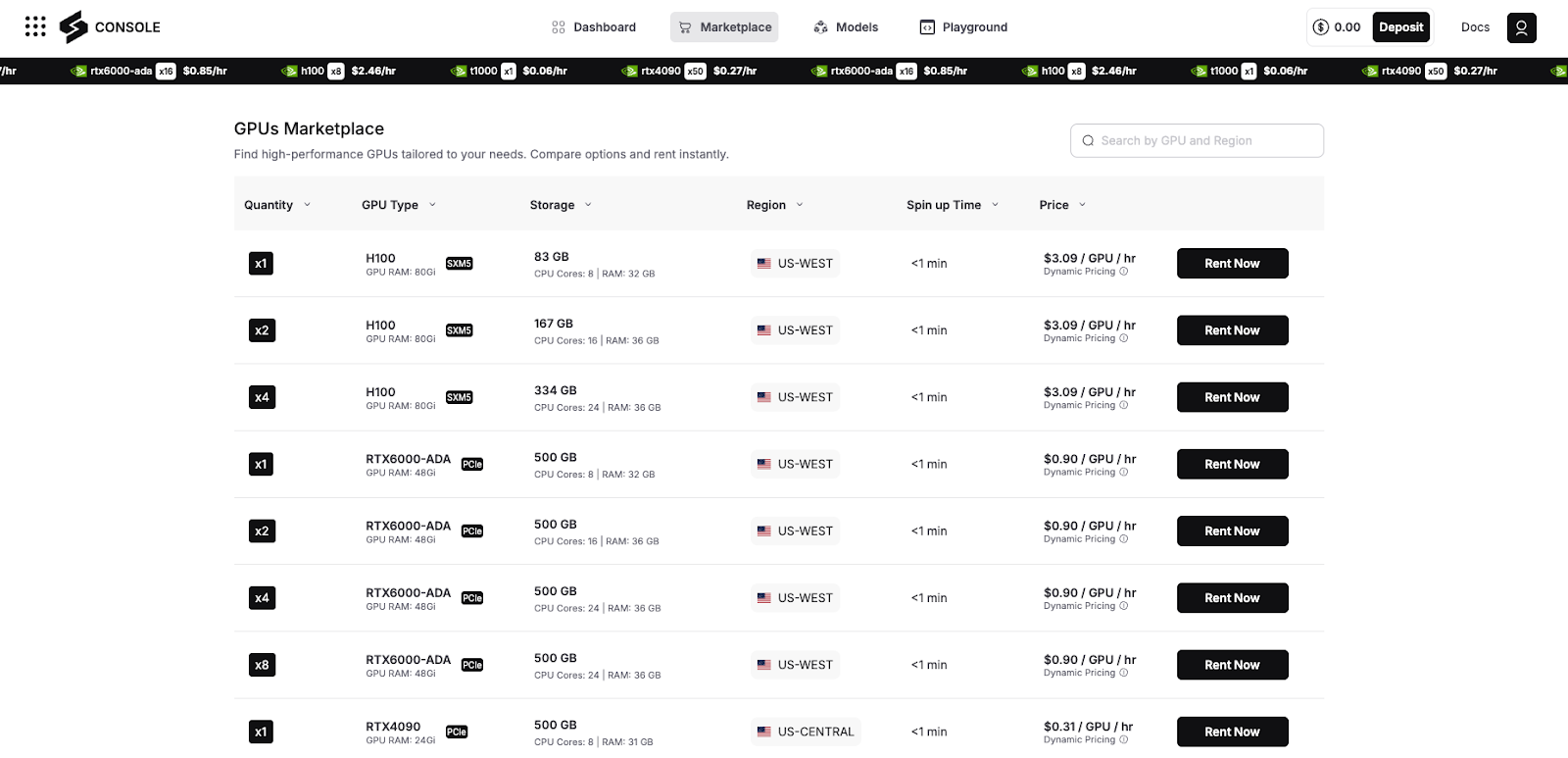
Why Spheron for You?
All these points lead to the main reason why someone should explore Spheron. It is not about big market numbers or grand hype. It is about real, everyday benefits. Developers can lower infrastructure bills by matching tasks to the right hardware level. They can cut down on setup time by avoiding multiple cloud services. They can move quickly between AI and Web3 projects. They can prepare for future changes by relying on a network that grows to include new hardware and frameworks. They can also manage workloads around the globe, reducing downtime by not being tied to a single data center.
Spheron does not promise to reinvent computing or dominate every market overnight. It focuses on bridging the gap between large cloud vendors and smaller data center operators. It curates a network of reliable providers and presents it in a single interface that is easy to learn. This calm, practical approach appeals to developers who want trustworthy solutions without the hype. When you sign up, you gain a set of tools that let you deploy, monitor, and scale your work across many machines. You see direct value in saved time, clear pricing, and peace of mind. That is why people who build AI models, who create Web3 applications, or who want an all-in-one solution should take a closer look at Spheron.








{kind=link}