
The development of artificial intelligence has brought about tremendous advancements in various fields, but running AI models can be incredibly resource-intensive, both financially and environmentally. AI models consume enormous amounts of electricity, and their energy demands are projected to grow as AI systems become more complex. For instance, in early 2023, running ChatGPT consumed around 564 MWh of electricity per day, equivalent to the daily energy usage of 18,000 U.S. households.
This vast consumption is largely due to AI models’ complex computations, especially floating-point operations in neural networks. These processes are inherently energy-hungry, involving heavy matrix operations and linear transformations. However, a revolutionary new algorithm promises to significantly reduce this energy load. It’s called L-Mul (Linear-Complexity Multiplication), and it could reshape the future of AI by making models faster and drastically more energy-efficient.
Let’s explore L-Mul, how it works, and what this means for the future of energy-efficient AI.
Why AI is Energy-Intensive
Neural networks are at the core of modern AI models, which use floating-point numbers to perform computations. These floating-point operations are essential for functions like matrix multiplications, which are critical to how neural networks process and transform data.
Neural networks typically use 32-bit and 16-bit floating-point numbers (known as FP32 and FP16) to handle the parameters, inputs, and outputs. However, floating-point multiplications are far more computationally expensive than basic integer operations. Specifically, multiplying two 32-bit floating-point numbers consumes approximately four times the energy required to add two FP32 numbers and 37 times more energy than adding two 32-bit integers.
Thus, floating-point operations present a significant energy bottleneck for AI models. Reducing the number of these floating-point multiplications without sacrificing performance can greatly enhance AI systems’ energy efficiency.
The Birth of L-Mul: An Energy-Saving Solution
This is where the L-Mul algorithm steps in. Developed by researchers and recently published on ArXiv, L-Mul simplifies floating-point multiplications by approximating them with integer additions. The key advantage? This algorithm can be seamlessly integrated into existing AI models, eliminating the need for fine-tuning and enabling substantial energy savings.
By replacing complex floating-point multiplications with much simpler integer additions, L-Mul achieves up to 95% energy reduction for element-wise tensor multiplications and saves up to 80% energy for dot product computations. This energy efficiency doesn’t come at the cost of accuracy either, making L-Mul a breakthrough for running AI models with minimal power consumption.
Understanding Floating-Point Operations
To better appreciate the impact of L-Mul, let’s take a closer look at the floating-point operations on which AI models rely. When you multiply two floating-point numbers, the process involves:
Exponent addition (O(e) complexity)
Mantissa multiplication (O(m²) complexity)
Rounding and normalization
The mantissa multiplication is the most resource-intensive part of this process, requiring significant computational power, which leads to high energy consumption. On the other hand, integer addition is far simpler and less energy-intensive, with a linear complexity of O(n), where n represents the bit size of the integers involved.
How L-Mul Works: Replacing Floating-Point Multiplications
The L-Mul algorithm simplifies this process by replacing floating-point mantissa multiplications with integer additions. Here’s how it works:
Two floating-point numbers (x and y) are represented by their mantissas (the fractional parts) and exponents.
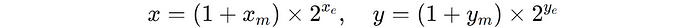
Instead of performing expensive mantissa multiplication, L-Mul uses integer additions to approximate the result.
If the mantissa sum exceeds 2, the carry is added directly to the exponent, skipping the need for normalization and rounding found in traditional floating-point multiplication.
This approach reduces the time complexity from O(m²) (for mantissa multiplication) to O(n), where n is the bit size of the floating-point number, making it far more efficient.
Precision vs. Computational Efficiency
In addition to being energy-efficient, L-Mul offers a high degree of precision. As AI models increasingly adopt 8-bit floating-point numbers (FP8) to reduce memory usage and computational cost, L-Mul shines as a highly effective alternative. FP8 has two common representations: FP8_e4m3 (more precise but with a smaller range) and FP8_e5m2 (less precise but with a larger range).
When compared to FP8, L-Mul outperforms in terms of both precision and computational efficiency. L-Mul offers greater precision than FP8_e4m3 while consuming fewer computational resources than FP8_e5m2, making it a superior alternative in many scenarios.
Real-World Applications of L-Mul
So, how does L-Mul perform in real-world AI tasks? Let’s break it down:
Transformer Models and LLMs
L-Mul can be directly applied to transformer models, particularly in the attention mechanism, where large-scale matrix multiplications occur. This application leads to up to 80% energy savings without sacrificing performance. No fine-tuning is required, which is a significant advantage.
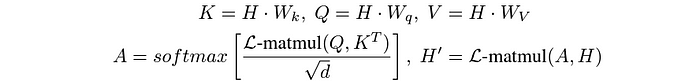
For instance, in large language models (LLMs) like Mistral-7b and Llama-3.1, L-Mul has been shown to outperform FP8 and Bfloat16, common floating-point formats used in transformers, across various benchmarks, including text-based and instruction-following tasks.
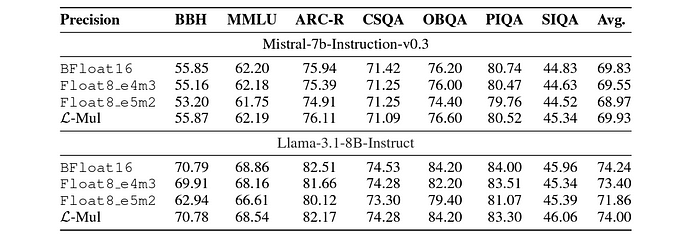
GSM8k and Other Benchmarks
When evaluated on specific tasks like GSM8k, which tests models on grade-school math problems, L-Mul consistently outperformed FP8 in terms of accuracy and efficiency. This demonstrates that L-Mul can handle complex mathematical reasoning without requiring excessive computational power.

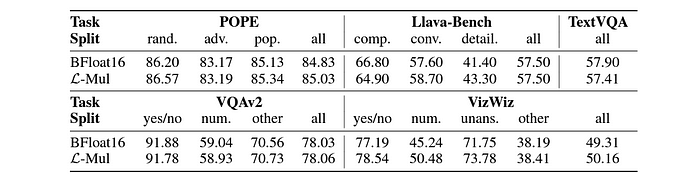
Visual Question Answering (VQA) and Object Detection
In models like Llava-v1.5–7b, which are used for visual question answering and object hallucination, L-Mul again surpassed FP8 in both accuracy and computational efficiency, reaffirming its utility in multimodal tasks that require a combination of text and image processing.
What the Future Holds for L-Mul
The ability to use L-Mul without fine-tuning and its remarkable energy savings means that it could become a key player in the future of AI development. It’s already clear that this algorithm can enhance the performance of models across multiple domains, from language processing to vision tasks, all while reducing the carbon footprint associated with AI computations.
The results are just as promising in models where fine-tuning is required. When tested on the Gemma2–2b-It model, L-Mul performed at the same level as FP8_e4m3, meaning that even fine-tuned models can maintain their accuracy while becoming more energy-efficient.
The future of AI is bright, but it also needs to be sustainable. With algorithms like L-Mul, we are on the path to creating smarter, faster, and greener AI systems.
Conclusion: A New Era of Energy-Efficient AI
The L-Mul algorithm represents a massive leap forward in developing energy-efficient AI. By replacing expensive floating-point multiplications with simpler integer additions, L-Mul reduces power consumption and improves computational efficiency and model performance across the board.
As AI advances and demands more computational power, solutions like L-Mul will be crucial for ensuring that progress does not come at an unsustainable cost to the environment.
Reference Reading
FAQs
What is L-Mul?
L-Mul stands for Linear-Complexity Multiplication, an algorithm that replaces floating-point multiplications with integer additions to improve energy efficiency in AI models.
How does L-Mul save energy in AI computations?
L-Mul simplifies the costly floating-point operations in neural networks, reducing energy consumption by up to 95% for tensor multiplications and 80% for dot products.
Does L-Mul affect the accuracy of AI models?
No, L-Mul maintains the accuracy of AI models while reducing their energy consumption, making it an ideal choice for energy-efficient AI systems.
Can L-Mul be integrated into existing AI models?
Yes, L-Mul can be seamlessly integrated into existing neural networks without any need for fine-tuning, making it a practical solution for enhancing energy efficiency.
How does L-Mul compare to FP8 in AI tasks?
L-Mul outperforms FP8 in both precision and computational efficiency, making it a superior alternative for many AI applications.






 Stablecoin: Forging a Path for Institutional Digital Finance")

{kind=link}